GSC’s Robots.txt tester can be wrong
Yes, you read that right and no it is not a clickbait!
This is the first time I have encountered an issue with GSC’s robots.txt tester. The tool claimed the URL(s) was blocked in robots.txt checker but as per URL inspector tool, GSC Crawl Stats and server logs, the page(s) were getting crawled.
The Back Story
While working on the monthly crawls for one of our clients we noticed that the crawler was taking too long for some reason. We had witnessed a spider trap on this particular project and wondered if it might have popped up again.
The URL(s) in question were a particular pattern of parameterized URLs generated from the faceted navigation. Something that you could find easily on most Ecommerce sites.
This was a medium sized site with around 3000+ pages with URLs generated from faceted navigation blocked intentionally.
With Screaming Frog crawler set to respect robots.txt, parameterized URLs wouldn’t be crawled normally. This hinted there was a problem with robots.txt instructions.
Please note: We’ll only discuss Googlebot in this article.
Reviewing the problem in GSC’s robots.txt
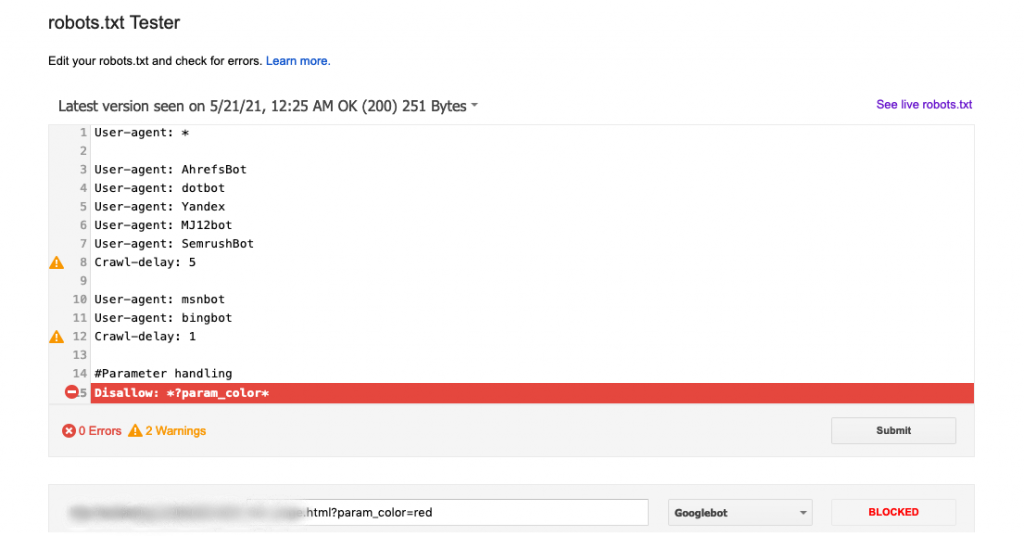
The first obvious check was using the GSC’s robots.txt tester to verify if the URLs were indeed blocked or not in the robots.txt.
As shown in the screenshot below, GSC’s robots.txt tester says the URL pattern is blocked for Googlebot.
What does GSC URL Inspector Tool say
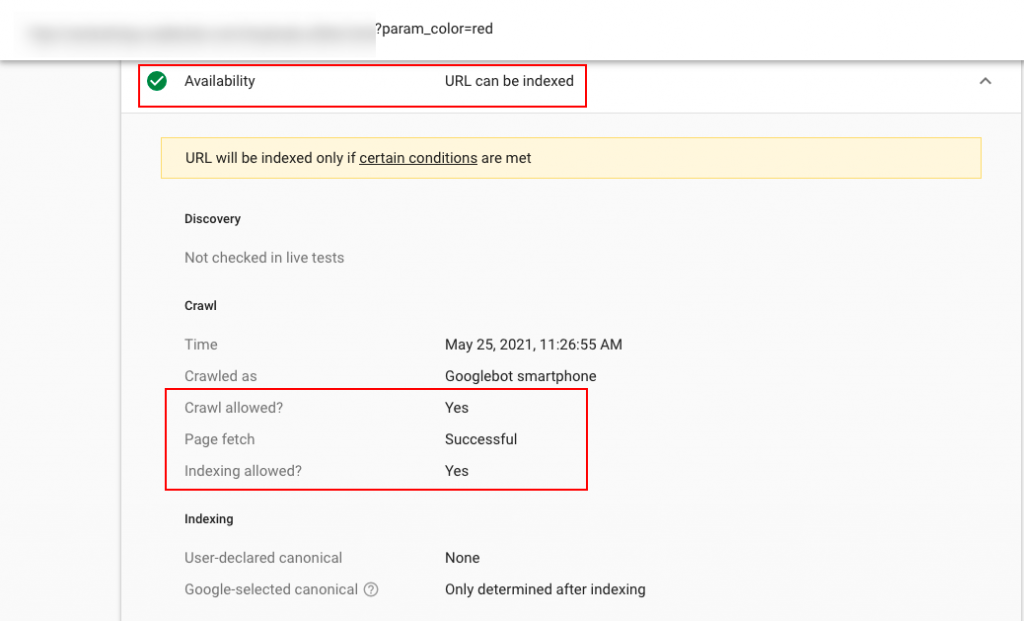
After the robots.txt tester says it’s blocked, the next check was to review the URL in the URL Inspector tool.
As shown in the screenshot below, the URL inspector says Crawl Allowed as Yes.
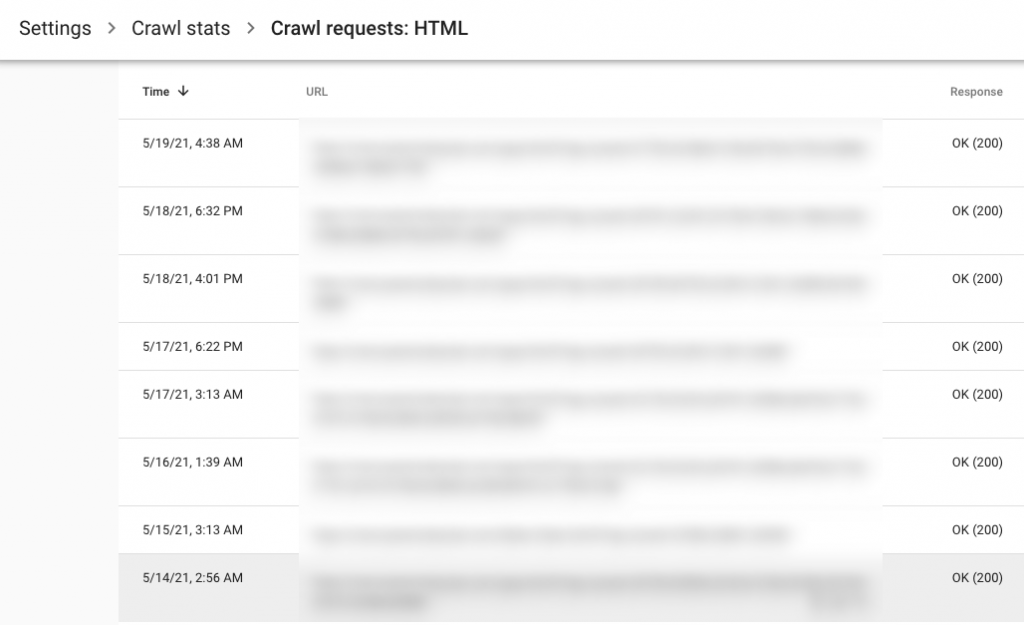
GSC Crawl Stats and Server Logs Data
So far it was looking like the URL(s) pattern in question can be crawled by Google. GSC’s Coverage reports already suggested that the URL had been crawled a while back.
However, can be crawled != is crawled.
Next step – confirm if the URL pattern was actually getting crawled by Googlebot or not actively.
As you will find in the screenshots below, both GSC Crawl Stats and Server Logs suggest the URLs were getting crawled.
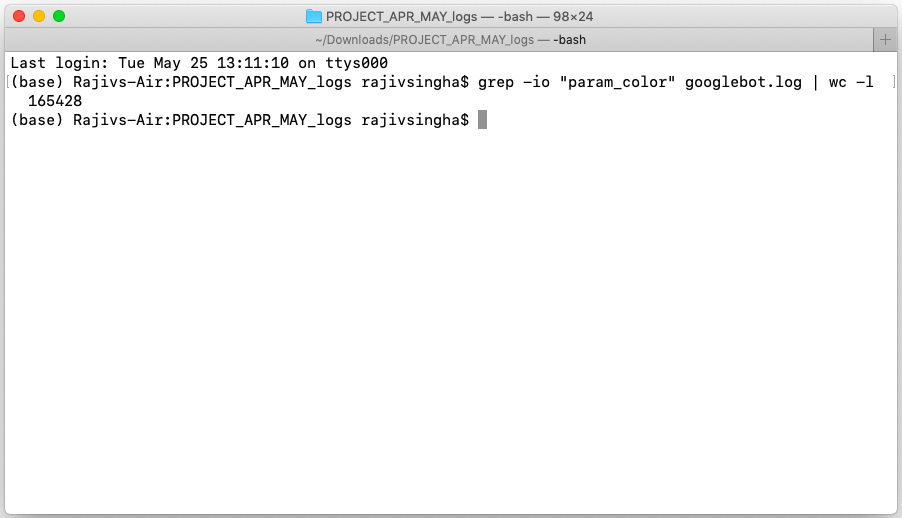
The above command in terminal counts the occurrence of string “param_color” in the log file “googlebot.log”
The real issue in robots.txt instructions
All evidence points to the fact that these URLs were getting crawled and it was undesired.
To confirm I tested the robots.txt instructions without any changes on two other external validators.
One of them marked the URL as allowed.
The other one marked it as blocked just like GSC’s robots.txt tester.
Here are the original instructions and the parameter in question is “param_color”.
User-agent: * User-agent: AhrefsBot User-agent: dotbot User-agent: Yandex User-agent: MJ12bot User-agent: SemrushBot Crawl-delay: 5 User-agent: msnbot User-agent: bingbot Crawl-delay: 1 #Parameter handling Disallow: *?param_color=* … #Rest of the instructions which do no matter here
Clearly, the issue was how the instructions were grouped.
As per robots.txt specifications related to grouping, the above instructions mean that all instructions after #Parameter handling apply only to the third user group i.e.
User-agent: msnbot User-agent: bingbot Crawl-delay: 1
This would mean the instruction Disallow: *?param_color=* doesn’t apply to Googlebot.
However, if you test these instructions on GSC’s robots.txt tester, it shows the URL will be blocked for Googlebot as shown in image 1 above.
Our assumption is that since Googlebot doesn’t consider “crawl-delay” the robots.txt tester behaves as if the crawl-delay instructions do not exist. One can say GSC’s robots.txt tester sees it like this:
User-agent: * User-agent: AhrefsBot User-agent: dotbot User-agent: Yandex User-agent: MJ12bot User-agent: SemrushBot User-agent: msnbot User-agent: bingbot #Parameter handling Disallow: *?param_color=* … #Rest of the instructions which do no matter here
Note: extra line breaks without any instructions are of no meaning and are discarded. This entire instruction set is treated as one single group by GSC robots.txt tester.
However, in reality, Googlebot reads the crawl-delay line and understands it is a logical instruction but simply chooses to ignore it. This makes it obey the grouping rules stated in the specifications.
The fix was simple after this discovery. Repeat the group of instructions for each of the three groups.
We tested the URL in the URL Inspector tool to ensure the fix was legit. Once the URL inspector validated that the URL can be crawled, we updated the robots.txt.
To Summarize
This interesting case is an example of how there is a mismatch between what GSC’s robots.txt says and how the actual Googlebot behaves. If you feel a URL is getting crawled even though it is blocked in robots.txt, do a Live test in GSC’s URL Inspector. If it says the URL can be crawled, then it means something is wrong with your robots.txt.
I hope this article helps you with some of the issues that you could run into while setting up your robots.txt. If you are unsure of how efficiently your website has been set up from an SEO perspective, an SEO audit might be the best path to pursue.
Please feel free to write to us at letstalk@cueblocks.com if you need any assistance with making your website SEO prepared.
- About the Author
- Latest Posts
I am part of the CueBlocks Organic Search(SEO) team. I love playing football and reading about Technical SEO.

Rajiv Singha
I am part of the CueBlocks Organic Search(SEO) team. I love playing football and reading about Technical SEO. LinkedIn
MORE POSTS-
Evaluating the Carbon Emissions of Shopify Themes
by Harleen Sandhu
Committing to green claims as a business is a huge promise to deliver on. For ecommerce stores, Shopify is leading …
Continue reading “Evaluating the Carbon Emissions of Shopify Themes”
-
Dark Mode: Accessibility vs Sustainable Web Design
by BalbirIntroduction Dark mode, a feature that lets users switch the color scheme of an app or website to darker colors, …
Continue reading “Dark Mode: Accessibility vs Sustainable Web Design”
-
Discover Essential Sustainable Marketing Principles and Strategies for Ethical Business Growth
by Pancham Prashar
Given the major issues that our world is currently facing, such as pollution and climate change, sustainability becomes an inevitable …
-
Show, Don’t Tell: Demonstrating Transparency in Your eCommerce Store
by Pancham Prashar
For an eCommerce brand committed to good, success goes beyond creating excellent products; it extends to effectively communicating your values …
Continue reading “Show, Don’t Tell: Demonstrating Transparency in Your eCommerce Store”
-
How to Market Sustainable Products Effectively
by Nida Danish
In today’s market, sustainability has evolved from a passing trend to a pivotal consideration for both consumers and businesses. Globally, …
Continue reading “How to Market Sustainable Products Effectively”
-
Decoding B Corp Marketing Challenges: Strategies for Success
by Nida Danish
Today, businesses place high importance on sustainability and ethical practices. For B2B and e-commerce leaders, being a certified B Corp. …
Continue reading “Decoding B Corp Marketing Challenges: Strategies for Success”
